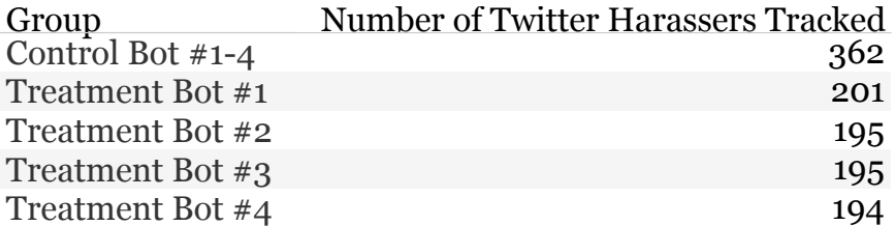Artificial Intelligence
We used active learning (machine learning) to collect enough tweets (dated 2017 and earlier) that humans such as Mechanical Turk women workers regard as gender harassment. That allowed our AI models to better learn and predict what humans regard as gender harassment language and symbols.
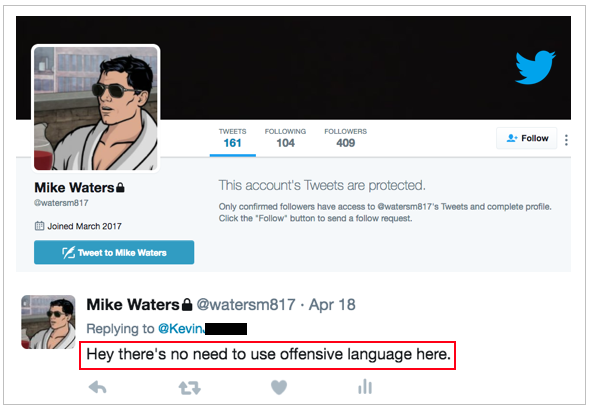
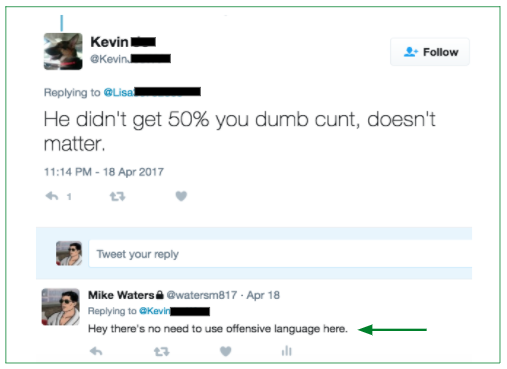
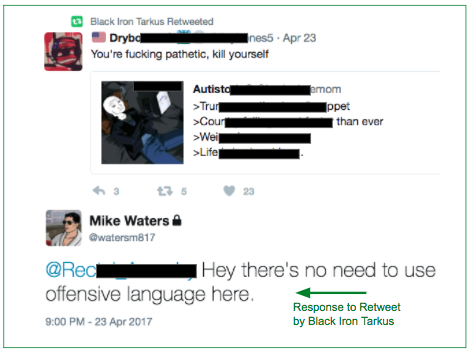
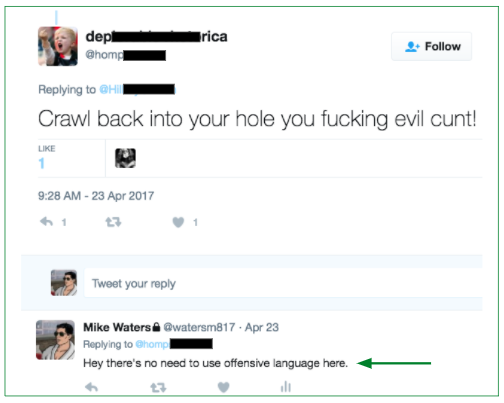
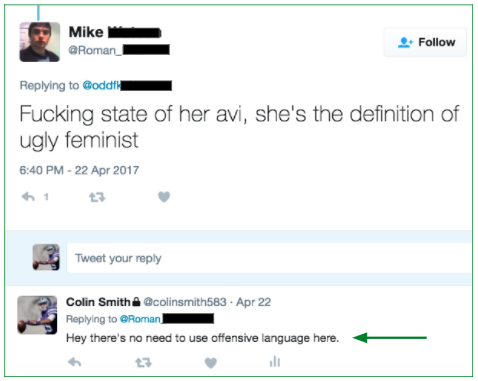
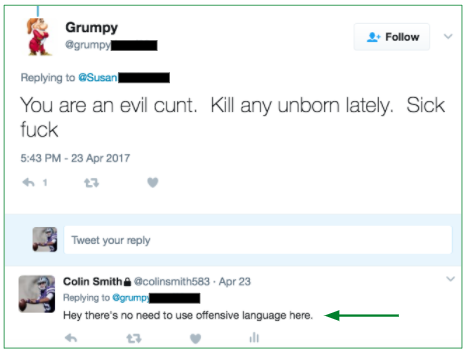
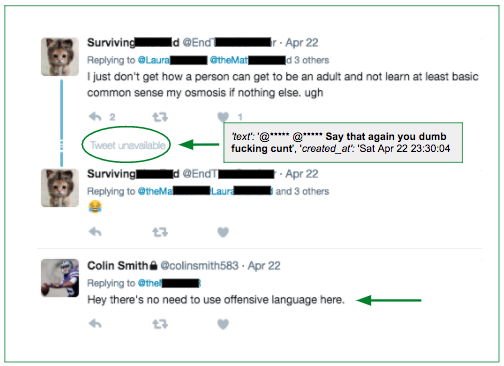
We found roughly 0.09% (9 out of 10,000) tweets are harassment. Rather than read through 10,000 tweets to find roughly 9 harassment ones, active learning (machine learning) helped us circumvent. We first labeled 1K tweets via various methods (i.e., Twitter live stream via API, Twitter keyword searches via API, harassment tweets via articles, etc.), then used our earliest baseline model (Logistic Regression) to output predicted probabilities on the tweets, before starting the cycle of active learning. Below are actual tweets we presented to an initial audience on 2/15/2017.
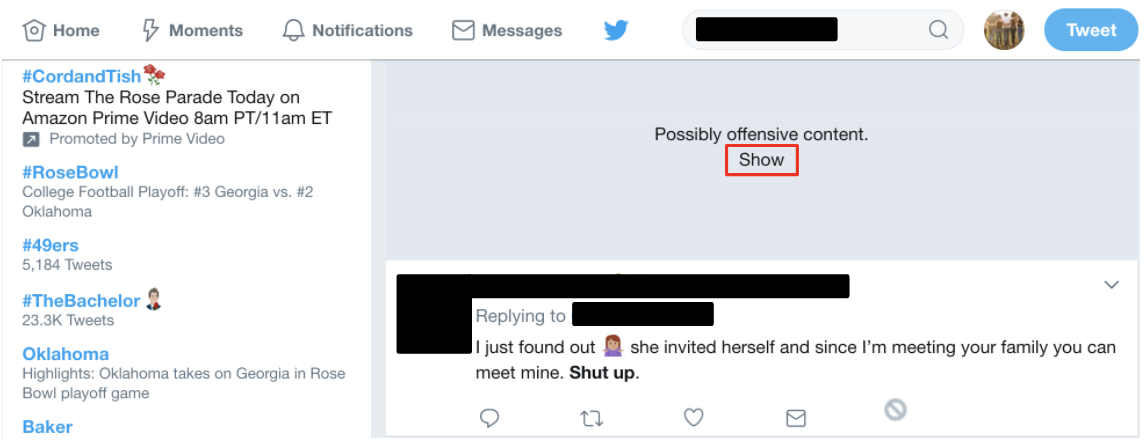
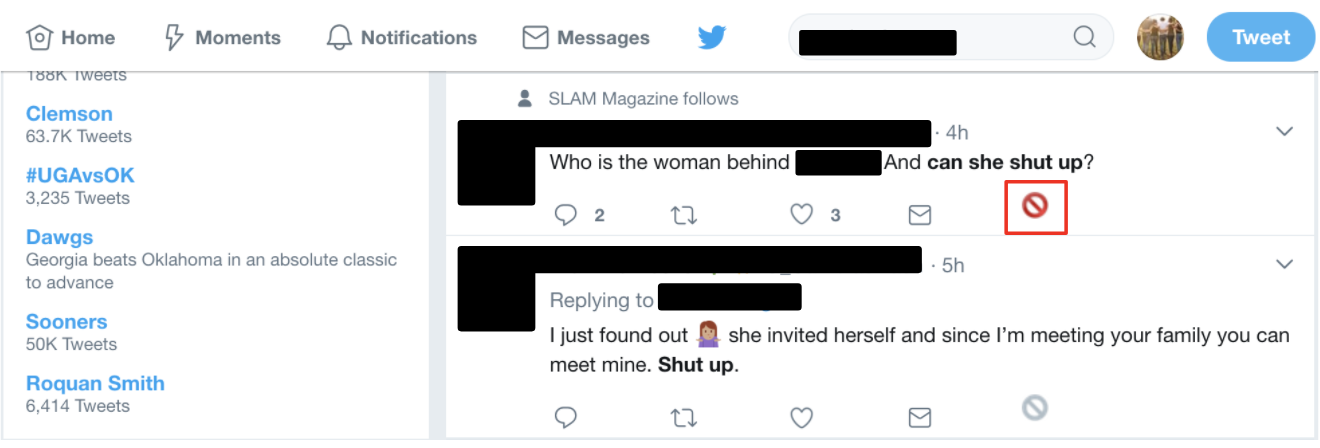
[If you prefer not to read what many regard as highly offensive / misogynistic tweets, please bypass the table below, and jump to the next circular diagram.]
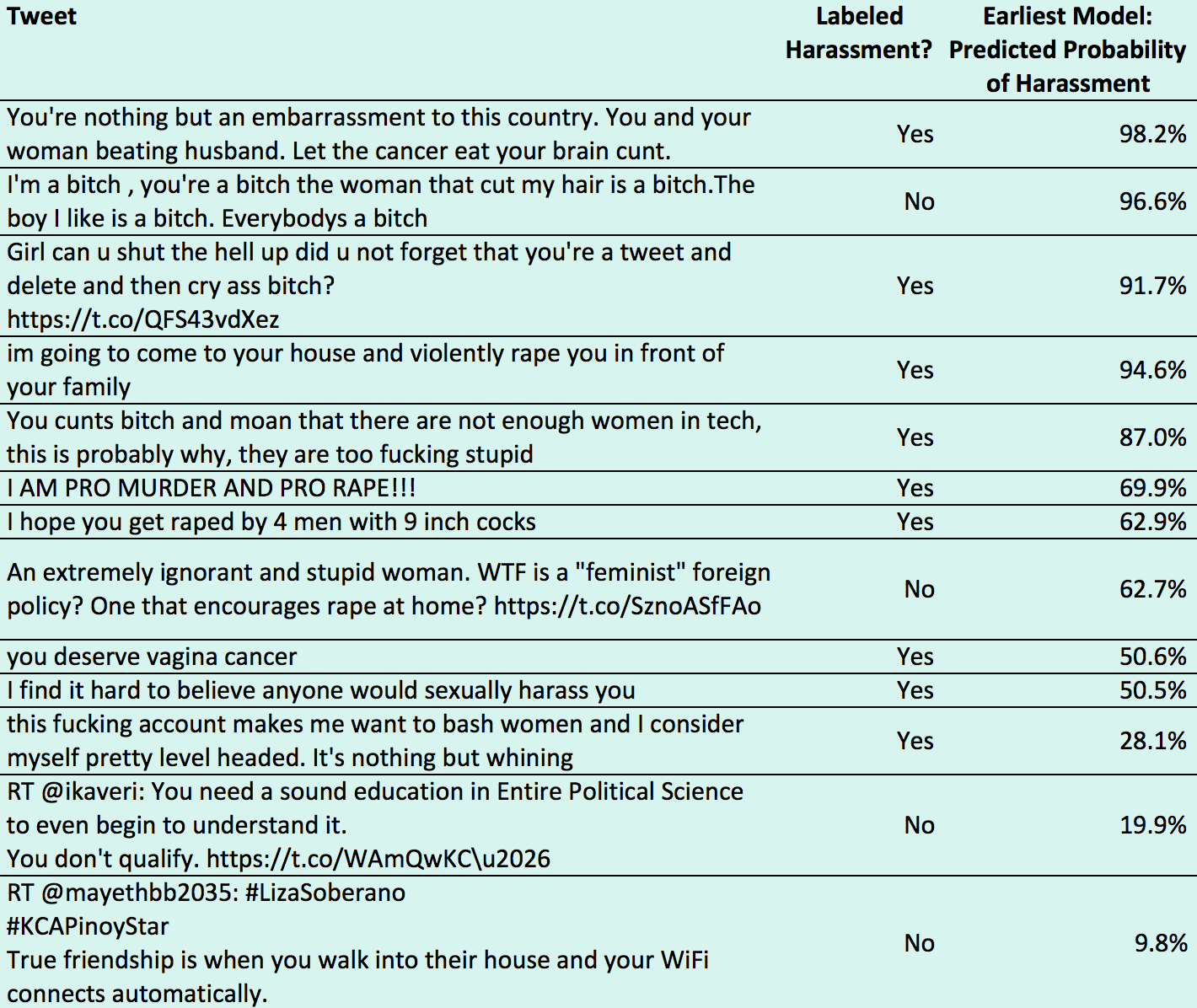
With active learning -- iteratively moving back and forth between data collection and machine learning -- we retrained our earliest baseline model, improving its ability to predict probability of harassment on past labeled tweets and new unlabeled tweets. For instance, our earliest model predicted the tweet, “you deserve vagina cancer”, at only 50.6% probability of harassment. As the model learned further, it eventually predicted that tweet with 70%+ probability of harassment. Our active learning process. . .
Our data collection process. . .

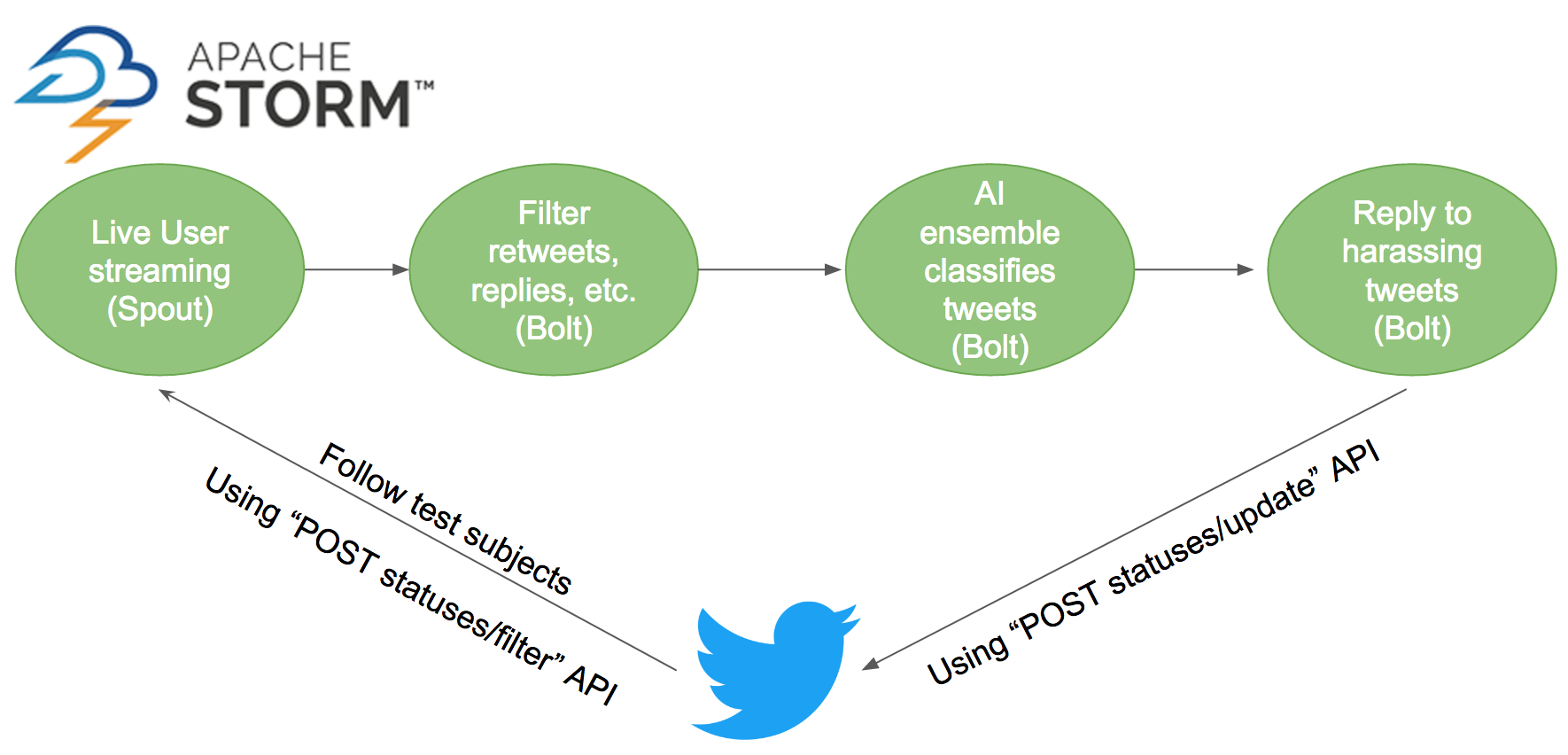
We chose to leverage and tune three categories of models: Gradient Boosting Decision Trees (GBDTs), Feed Forward Neural Networks (FNNs), and Logistic Regression (LR). And we sought not the best single model but the best combination of models. Our artificial intelligence process. . .
Rather than take a tweet's predicted probability of harassment from one model, we took a tweet's average predicted probability of harassment across multiple models for better reliability. Different models can make different mistakes in predicting the likelihood that tweets are offensive. For instance, for specific tweets, two models might predict low probability of gender harassment incorrectly, whereas six models might predict high probability of gender harassment correctly. By taking their average, the models can compensate for each other.
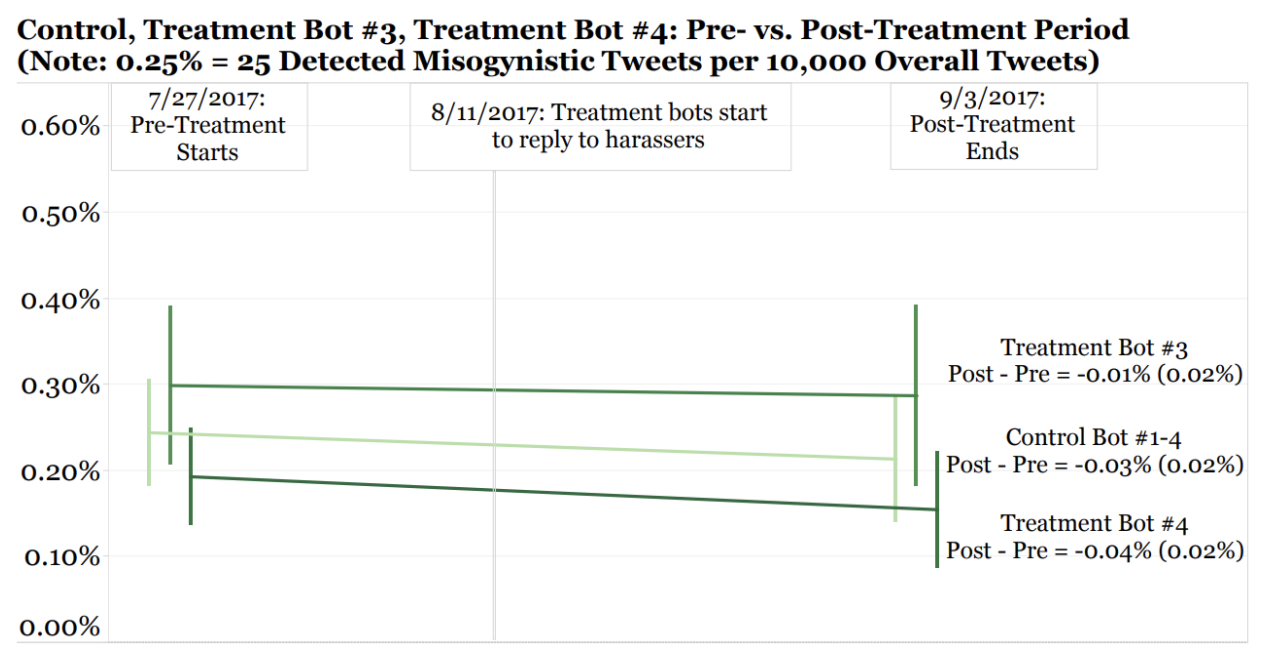
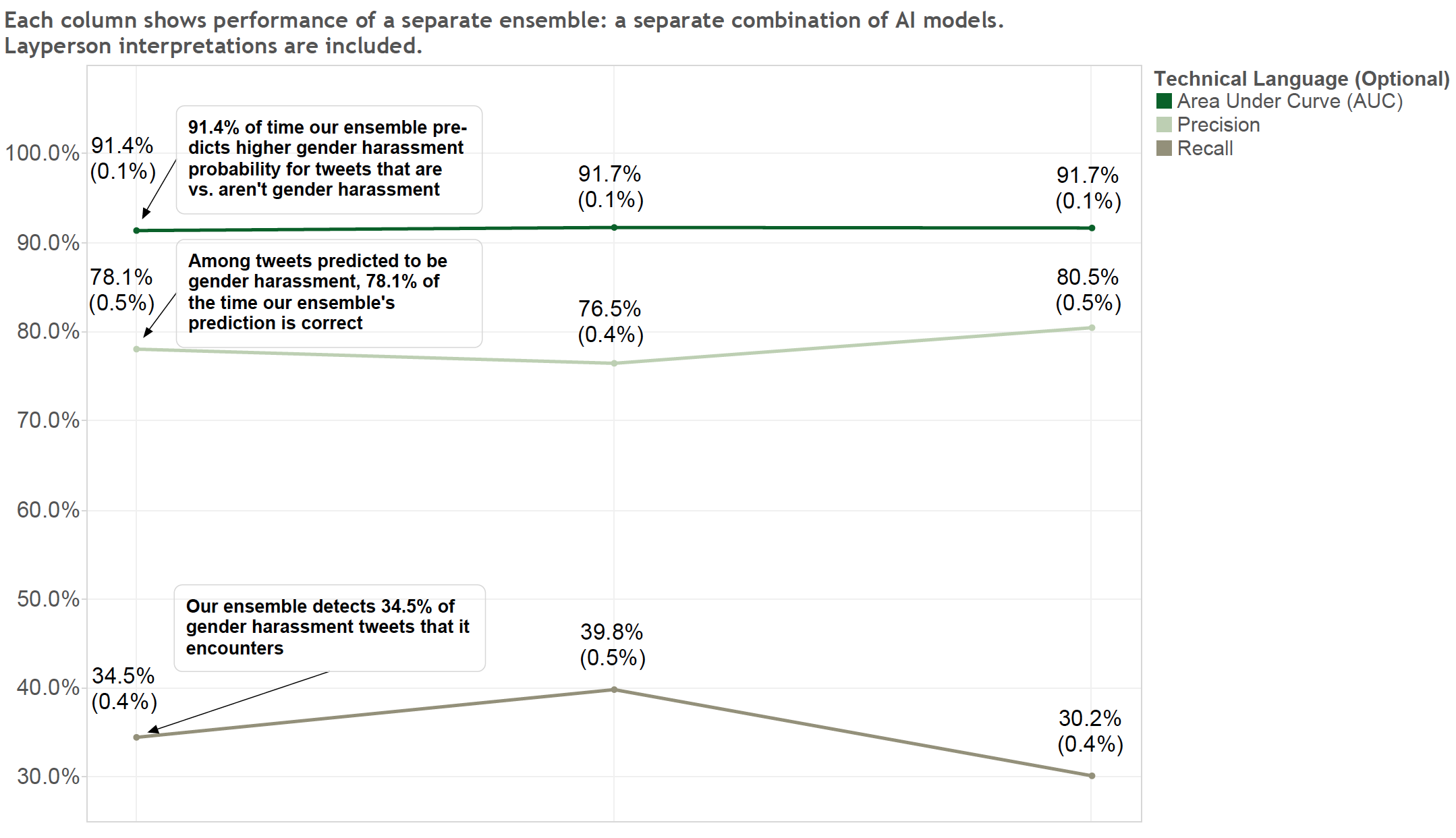
We used an automated approach that viewed the results of thousands of ensembles (where one ensemble refers to one combination of models). The graph below shows results for three separate combinations of models. The combination in the leftmost column is tied to our user-facing products: the Twitter Bot and Gender Harassment Tweets Blocker. Note, our flexibile approach allows replacement of one ensemble with another ensemble, if users and stakeholders prefer different performance. [Technical Language (Optional): As an interim step, we trained our final ensemble on the labeled train + validation data, then ran it on the labeled test data once (AUC: 91.3%, Precision: 78.9%, Recall: 32.5%). Then we proceeded to create a sampling distribution of results. Our final ensemble and specific alternative ensembles were eventually retrained on all labeled data (train + validation + test data), before linking our final ensemble to our user-facing products in the wild.]
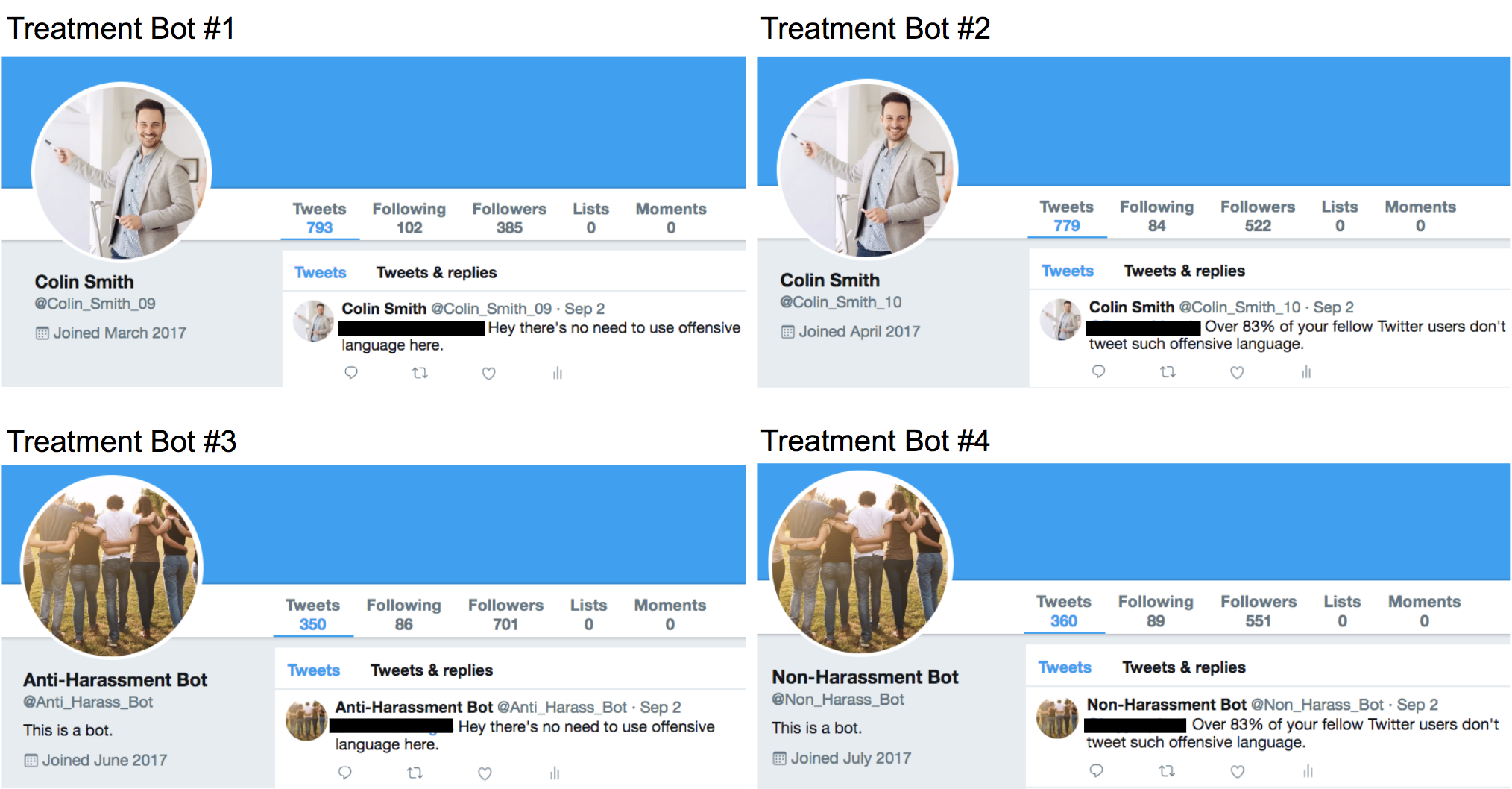
As we collect more labeled tweets via various channels, including via the Gender Harassment Tweets Blocker, our ensemble of models should improve even further.
[Technical Language (Optional): Our final models analyze words, not characters, despite our preference for some models in our ensemble to analyze characters. For instance, we initially analyzed characters as well, leveraging vectorizer "analyzer='char'" with random search across "ngram_range=(1,4)". Some of our initial GBDT models achieved about 95%+ precision and 80% recall. However, GDBT feature importances revealed some single characters such as " ' " took too much importance in the predicted probability of harassment, despite limited occurrences. So, we concluded a larger dataset than 18.8K tweets seems necessary to analyze characters in the future, and should not use that character-level method until then. Thus, to be fair and reasonable, we discarded ensembles which use that method and yield better results, and instead selected ensembles that both perform well and should generalize to new tweets in the Twitter universe. As revealed in the graph above, we built a sampling distribution to show not only our averages, but our standard errors around those averages. The small standard errors indicate each ensemble's consistent performance on 15 cross-validation samples of 6K+ tweets. 15 samples were derived from randomizing seed for 5 iterations and, within each iteration, implementing 3-fold cross-validation.]
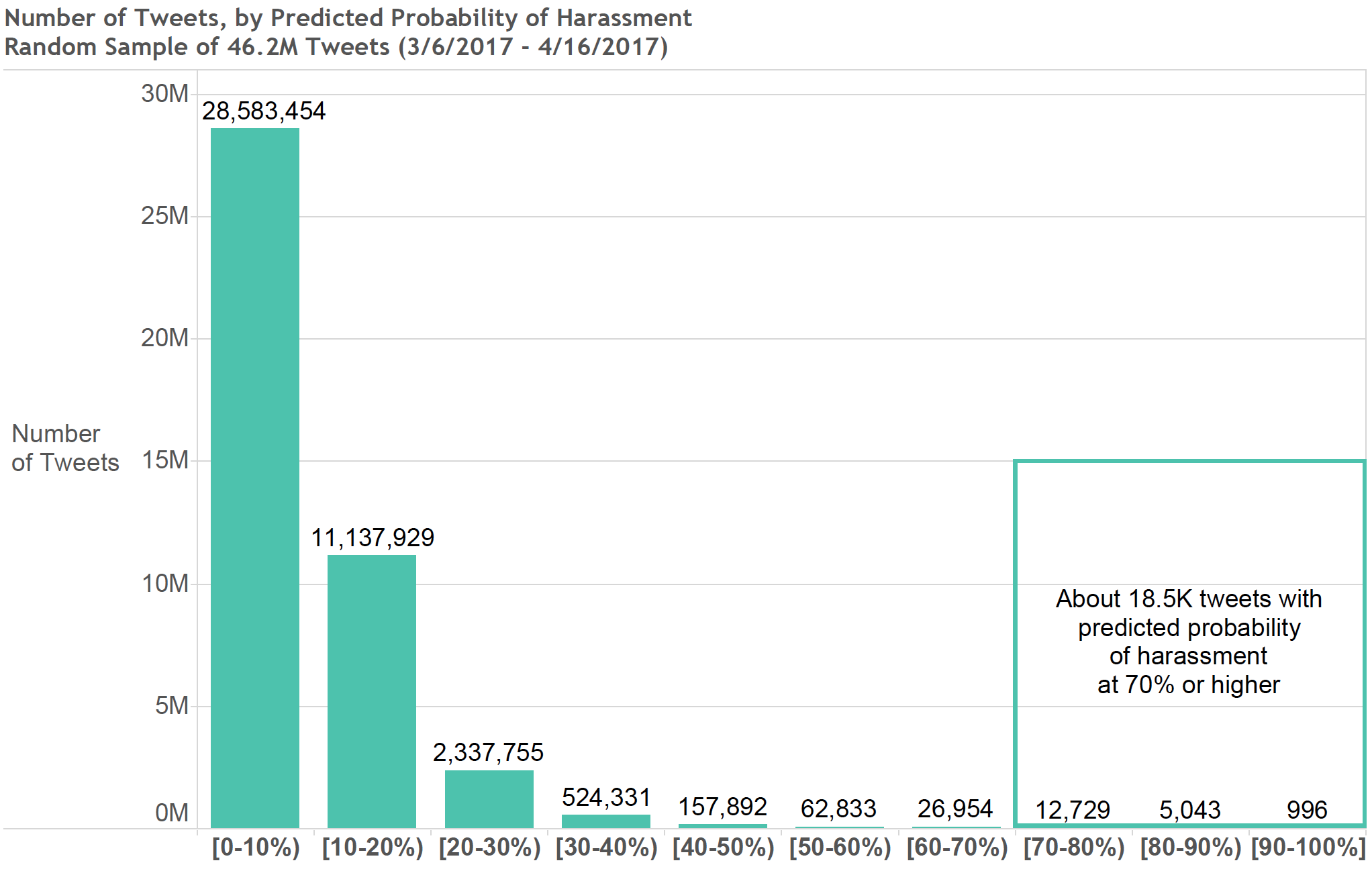
Our combination of 8 models (5 GBDTs, 2 FNNs, and 1 LR) yielded gender harassment probabilities across a sample of 46.2 million tweets. . .
If users collectively tweet an average of 500 million times a day (
David Sayce, November 2016 | ;
Business Insider, June 2015 | ), our products (if scaled) could have not only detected but responded to around 1.18 million tweets per week. In full transparency, that also means our products could have incorrectly flagged about 331,000 tweets per week. However, the AI underlying our Twitter Bot and Gender Harassment Tweets Blocker can allow more correct predictions currently (if exchanged for lower detection rates of harassment tweets). For instance, users of the Gender Harassment Tweets Blocker can change the default of 0.70 (hiding tweets with a 70%+ chance of harassment) to 0.85 (hiding tweets with an 85%+ chance of harassment) to have less tweets incorrectly flagged as gender harassment.
Projected number of harassment tweets that our AI could have detected on Twitter's full dataset (3/6/2017 - 4/16/2017)
The horizontal green line refects the projected average of 168K harassment tweets a day across the 6-week timeframe